Claude Code and Anthropic models on AWS Bedrock: Lessons learned
Claude Code is currently one of the major coding AI harnesses, if not the major one. Many organizations choose to use Claude Code not through Anthropic plans but through hosted Anthropic models on third-party cloud providers. AWS Bedrock is an example of a service that provides a large catalog of various LLMs, including the latest Anthropic models such as Opus, Sonnet and Haiku.
Recent articles have found that Claude subscriptions are drastically more economically efficient (examples one, two), so why would anyone prefer to pay more for API billing? There are a few reasons:
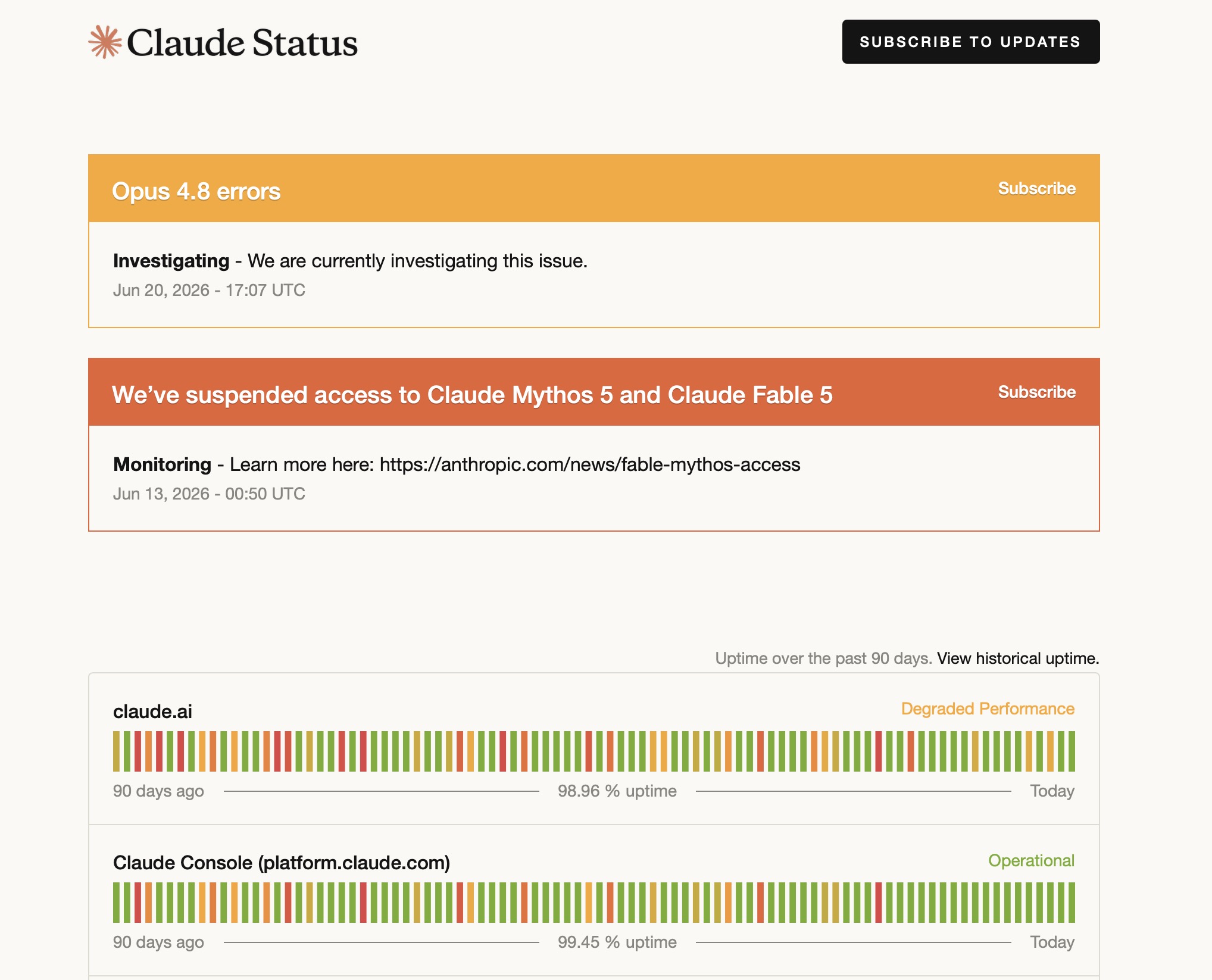
- Reliability: Anthropic services are still volatile enough to matter for critical operational workflows. At the time of writing, the public Claude status page was showing degraded performance for Claude API and Claude Code during an Opus 4.8 incident; the same status snapshot showed
claude.aiat 98.96% uptime and Claude Console at 99.45% uptime over the previous 90 days. In our experience, Bedrock is far more reliable. Its cross-Region inference can automatically route requests to another AWS Region and use compute across Regions to handle unplanned traffic bursts. This can be crucial for latency-sensitive applications.
- Compliance and security: Organizations that have compliance requirements related to third-party data processing (GDPR) need to be careful not to send any user or customer information to third-party services. If you already use AWS, then by using Opus on Bedrock, no data leaves the cloud boundary. With minimal setup, the LLM traffic doesn't leave your cloud either.
- Logging and observability — using application inference profiles, which are simply pointers to specific models that annotate requests with a predefined set of tags, you can easily track model usage, group by internal user, etc. You also have a way to enable logging of all Bedrock model invocations for security auditing and analysis using model invocation logging
Application inference profile
When a Bedrock caller (AWS SDK, AWS CLI, HTTP) wants to use an LLM, it specifies one of the following:
- An AWS-defined inference profile (looks like
arn:aws:bedrock:<source-region>:<account-id>:inference-profile/global.anthropic.claude-opus-4-8) - A custom inference profile created by you (looks like
arn:aws:bedrock:<region>:<account-id>:application-inference-profile/<application-profile-id>)
Custom application inference profiles are used to "wrap" model use with a predefined set of tags. A typical CloudFormation resource looks like this (docs)
Resources:
ServiceAOpusProfile:
Type: AWS::Bedrock::ApplicationInferenceProfile
Properties:
Description: Service A uses Opus 4.8
InferenceProfileName: internal-service-a-opus
ModelSource:
CopyFrom: arn:aws:bedrock:<source-region>:<account-id>:inference-profile/global.anthropic.claude-opus-4-8
Tags:
- Key: owner-team
Value: team-x
- Key: environment
Value: production
- Key: service_name
Value: service-a
Here we specify the description, which model is used (Opus 4.8 in our example), and a list of tags. As soon as the profile is created, you specify its ARN in Claude Code or in the Bedrock invocation.
Permissions
To be 100% sure that the caller can only use the inference profile to invoke the model, you need to set the permissions properly.
# Allow calling our inference profile
- Effect: Allow
Action:
- bedrock:InvokeModel
- bedrock:InvokeModelWithResponseStream
Resource:
- arn:aws:bedrock:<profile_region>:<account_id>:application-inference-profile/<profile_id>
# Allow calling the foundation models in all regions (note `*`)
# but only through our inference profile (note `Condition`)
- Effect: Allow
Action:
- bedrock:InvokeModel
- bedrock:InvokeModelWithResponseStream
Resource:
- arn:aws:bedrock:*::foundation-model/<model_id>
Condition:
StringLike:
bedrock:InferenceProfileArn: arn:aws:bedrock:<profile_region>:<account_id>:application-inference-profile/<profile_id>
# Allow fetching the inference profile and model metadata descriptions.
# Narrow down the 'Resource' if you need to.
- Effect: Allow
Action:
- bedrock:ListFoundationModels
- bedrock:GetFoundationModel
- bedrock:ListInferenceProfiles
- bedrock:GetInferenceProfile
Resource:
- '*'
This ensures that the caller must use an inference profile to call the model, and hence the tags will propagate properly.
Tip: you can use the following AWS CLI command to debug Bedrock permissions on a developer machine (it says hello to Opus 4.7):
aws bedrock-runtime converse \
--region us-east-1 \
--model-id global.anthropic.claude-opus-4-7 \
--messages '[{"role":"user","content":[{"text":"Say hello in one short sentence."}]}]' \
--query 'output.message.content[0].text' \
--output text
Lesson 1: use application inference profiles for services, not people
If your COO sees these Bedrock usage reports, they will have questions. So use application inference profiles for all workloads in your organization to make spending transparent. Before:
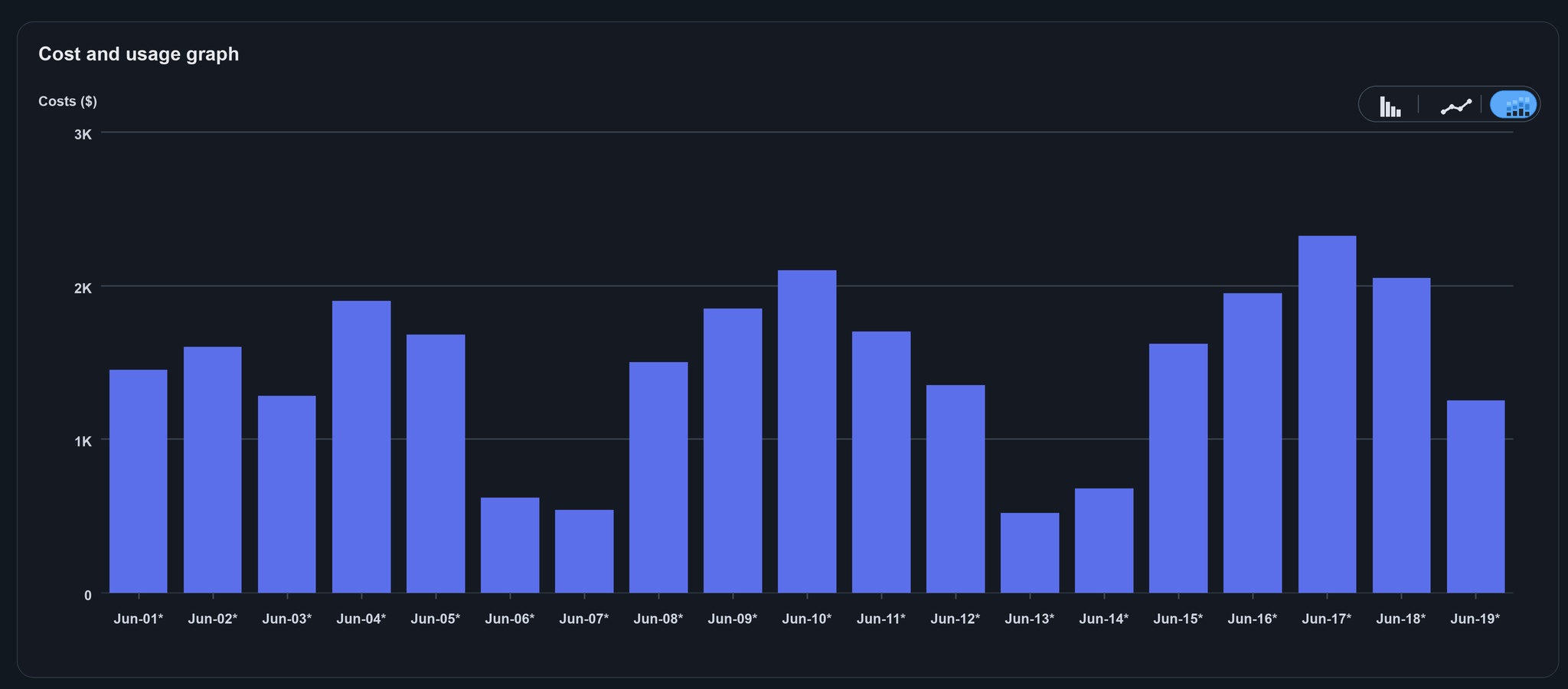
After:
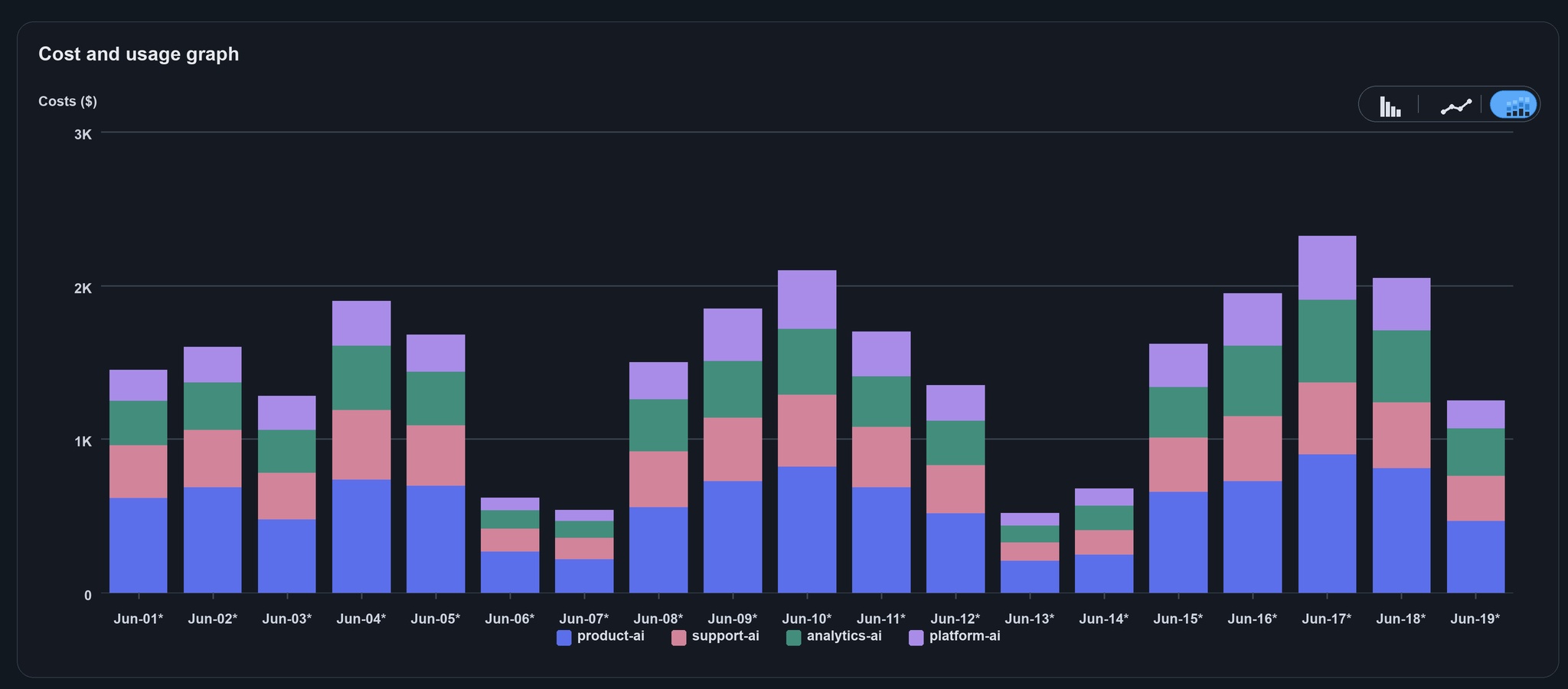
Lesson 2: don't use custom inference profiles for human usage
Claude Code integration with AWS Bedrock supports custom application inference profiles:
export CLAUDE_CODE_USE_BEDROCK=1
export ANTHROPIC_DEFAULT_OPUS_MODEL="arn:aws:bedrock:<region>:<account_id>:application-inference-profile/..."
export ANTHROPIC_DEFAULT_SONNET_MODEL="arn:aws:bedrock:<region>:<account_id>:application-inference-profile/..."
export ANTHROPIC_DEFAULT_HAIKU_MODEL="arn:aws:bedrock:<region>:<account_id>:application-inference-profile/..."
However, it's very cumbersome to manage them in the age of rapidly evolving models because
- Frequent updates: Models are released frequently — you'll need to create inference profiles regularly. People tend to prefer to switch to the latest models quickly.
- Multiple dimensions: Your organization may have multiple teams — you'd want to create and manage not one but X inference profiles for each LLM model and distribute them somehow
- Technical savviness: People in your organization may have different levels of technical skill. Setting up inference profile environment variables or configs may be harder for people who don't work in engineering regularly
How do you track spending then? You have the following options:
- Use a third-party LLM gateway: LiteLLM, Portkey, Bifrost to name a few. These services act like proxies between the caller and Bedrock, simplifying authentication, MCP management and letting you set up budgets per user. Go that way if you have extra money!
- Pros: these services have everything out of the box, let you specify concrete budgets, and enforce them in real time.
- Cons: typically, such services are not free when you need any security feature (such as OAuth integration).
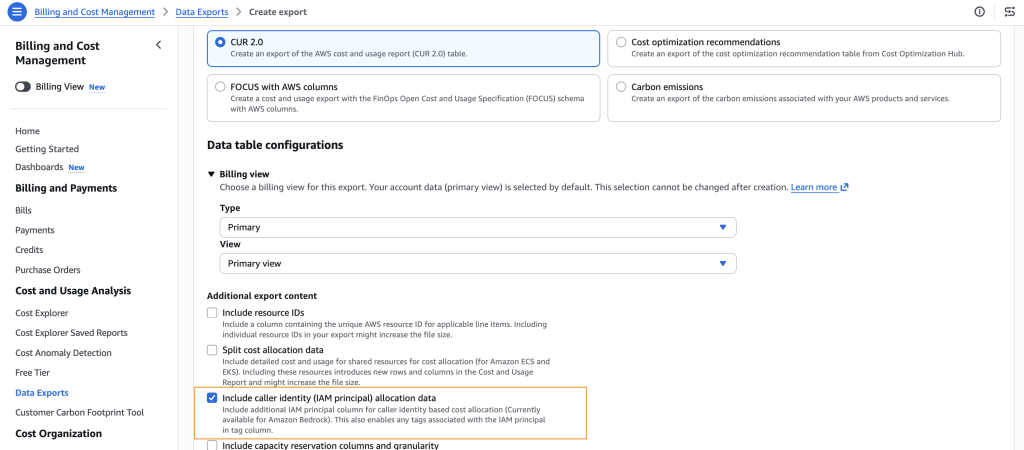
- Set up a CUR 2.0 export in AWS Cost Explorer and enable caller identity in the export. That way you'll get per-IAM session granularity in the export that will let you compute per-user spending.
- Pros: the figures are 100% accurate and match your cloud bill
- Cons: 24-hour latency
 * Enable Bedrock invocation logging and track usage in real time
* Pros: near-real-time log delivery with accurate token counts and user identity
* Cons: This is highly sensitive data! You need to restrict access and implement the processing yourself, e.g. using AWS Lambda and a database.
* Enable Bedrock invocation logging and track usage in real time
* Pros: near-real-time log delivery with accurate token counts and user identity
* Cons: This is highly sensitive data! You need to restrict access and implement the processing yourself, e.g. using AWS Lambda and a database.
Lesson 3: enable invocation logs
For the purpose of usage tracking, I stripped out much of the information stored in the logs. It looks like this:
{
"timestamp": "2026-06-16T12:00:56Z",
"accountId": "...",
"region": "us-east-1",
"requestId": "...",
"operation": "InvokeModelWithResponseStream",
"modelId": "...",
"input": {
...
"inputTokenCount": 528,
"cacheReadInputTokenCount": 1058,
"cacheWriteInputTokenCount": 0
},
"output": {
...
"outputTokenCount": 259
},
"identity": {
"arn": "arn:aws:sts::0123456789:assumed-role/<role-name>/john.doe@yourorg.io"
},
"inferenceRegion": "eu-north-1",
"schemaType": "ModelInvocationLog",
}
See that you have cacheRead, cacheWrite, input and output token counts, and identity.arn identifies the user that made the request. The final cost can be computed if you multiply these figures by the pricing. This approach works if the user uses any AI harness, not only Claude Code, because they all call AWS Bedrock in the end.
In addition to that, the logs store the whole payload of the request, which means that you can track
- What models are used by your engineers
- What MCP servers and Skills are popular
- What the typical context size of the first message is (this helps to determine inefficiencies)
- How many messages are in the sessions (this helps to determine if someone abuses the development agent)
- Real-time spending alerts sent to Slack
and many more.
Conclusion
Using AWS Bedrock as a provider of Anthropic models for your organization doesn't come cheap, but it provides you with more control over spending, permissions, security and analytical capabilities.
Comments
0 published comments
No published comments yet.
Leave a comment
Comments are published after review.