Building data platform in PySpark — Python and Scala interop

According to multiple recent surveys (as of 2021), Python is among the most widely used programming languages and its share of users is still growing. The State of Developer Ecosystem 2021 shows that it is the most adopted language among data scientists and ML engineers. Today, Python is the de-facto standard in the data industry.
Apache Spark is an excellent choice for modern data platforms which require massively parallel processing petabyte-scale datasets. Although it has Python (PySpark), Java, and R interfaces, it is developed in Scala and interfaces best with JVM-based languages. That’s why sometimes it’s helpful to develop some parts of your Spark application in Scala.
In these articles, we’ll provide you with some techniques to build a data platform using PySpark. The platform leverages existing Spark/Java/Scala business logic. It provides users with an easy way to develop, run, deploy and schedule PySpark jobs that interop with Scala libraries.
Why bother using JAR dependencies in PySpark?
Poor performance of Python UDFs
Sometimes your business logic is hard to express in Spark SQL terms, so putting it to a UDF seems to be a fine choice. However, using UDF comes at a cost.
When Spark job uses DataFrame API, each job can use Tungsten as the backend for the execution engine. With Tungsten, you get
-
Off-Heap memory management: memory is managed directly by the engine, which means no GC
-
Local in-memory layout: this improves cache-locality, making the CPU wait less and work more efficient
-
Code generation: the bytecode of the computation is compiled at runtime, benefiting from SIMD instructions, avoiding virtual calls, and using modern CPU and compiler features.
This magic stops working when your execution plan reaches a UDF call. Since the logic in our case is expressed in either Scala or Python, Spark execution engine is forced to
-
Make a call
-
Deserialize the result back to the efficient format.
For example, the following queries generate drastically different plans
import pyspark.sql.functions as f
import pyspark.sql.types as T
df = spark.createDataFrame([
{"key": "one"},
{"key": "two"},
])
# Using native Spark function
df.select(f.upper("key")).show()
# Using a Python UDF, here Python interpreter will
# be invoked on executors with extra serialization step.
upper_udf = f.udf(lambda s: s.upper(), T.StringType())
df.select(upper_udf("key")).show()
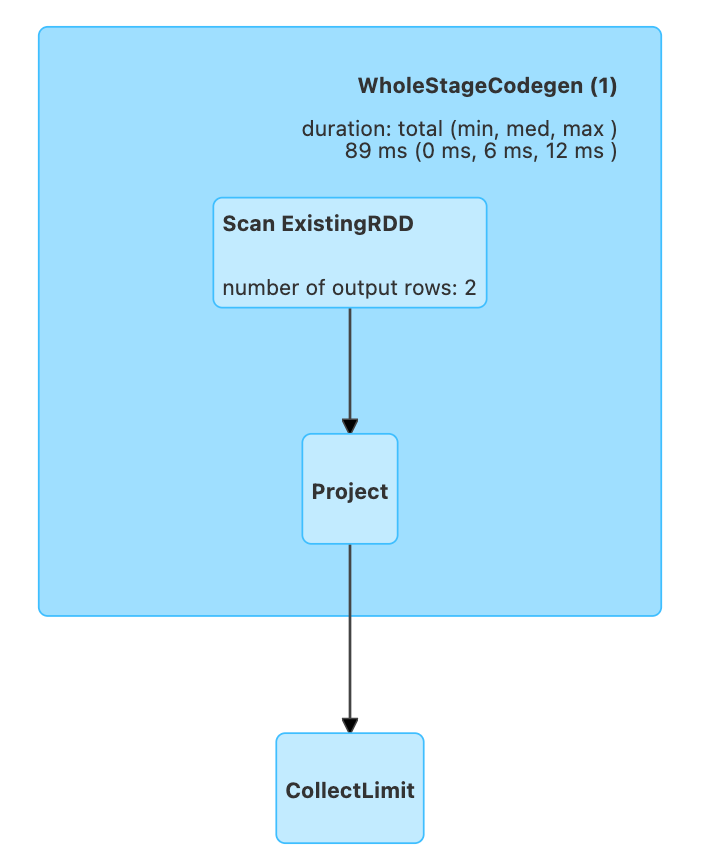
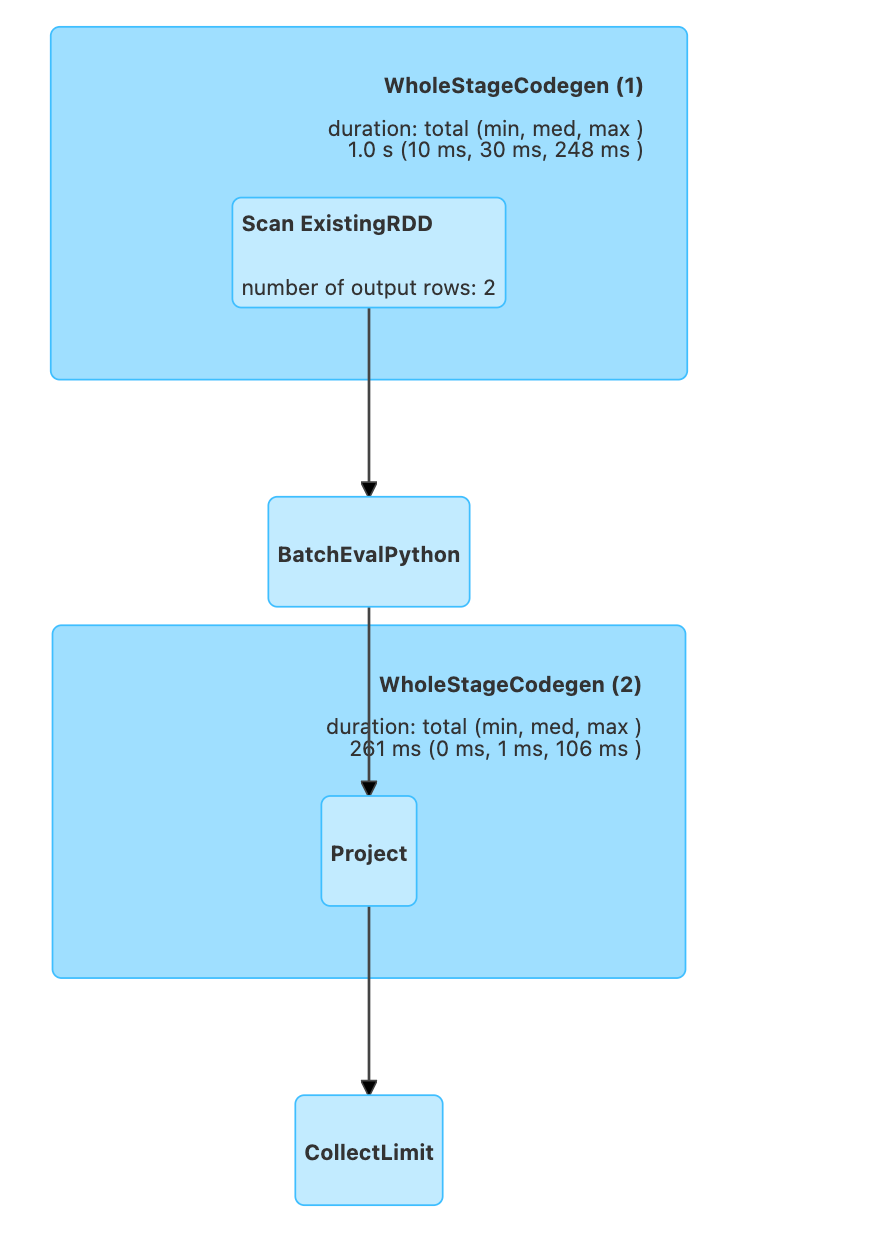
If you need to improve the performance of PySpark UDF, you have three options:
-
You may look closely at the implementation and double-check that you cannot express it in Spark SQL operations. Seriously, more than a half of UDFs I encounter can be rewritten to SQL.
-
If you’re lucky to use Spark 3 or a more modern version, you should consider using PySpark Pandas UDF, which lets you use Pandas and NumPy vector operations. Make sure you’ve enabled Apache Arrow support (spark.sql.execution.arrow.pyspark.enabled ) as it eliminates the need for serialization/deserialization step when Spark Partition gets converted to a Pandas object.
-
If the two options above don’t work for you, you should consider implementing your UDF in Scala or a custom Spark operator with native performance. We will discuss how to use them from Python below.
Use of explicit partitioning
Sometimes PySpark partitioning API is not enough for you. The possible use cases are
-
You want to provide Spark with additional metadata during reading so the framework knows the data layout.
-
You want more fine-grained control over repartition or repartitionByRange operation or to get rid of extra shuffle via using repartitionAndSortWithinPartition without Python code calls
I’ll link here an excellent article on squeezing everything from Spark partitioning API by my colleague. Still, I will mention that these optimizations are only available in JVM languages since PySpark doesn’t give this level of control.
Java/Scala libraries
There are some great libraries in the Java world that supplement Spark very well. Some of the examples we’ve found useful:
-
Deequ — is a lightweight library that lets you define unit tests for your data via expressing the constraints to check (however, there’s a Python library deequ-python which is seems to be poorly supported). Great expectations framework looks like a viable alternative, but to my knowledge, it is less lightweight and not as straightforward to use.
-
Until Delta Lake 1.0, the entire API had only been available as a Scala library. Future state-of-the-art Spark-related technologies will probably support the Scala interface from day one due to the implementation of Spark.
How to use Scala API from Python

Let’s create a simple Spark library in Scala. The following class has a single method that, given a string columnName and an integer rangeUntil, returns a Spark DataFrame with a single column named columnName with values 0...rangeUntil
package org.sergey
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.{functions => f}
case class Record(value: Int)
class MySparkLibrary {
def rangeDataframe(
spark: SparkSession,
columnName: String,
rangeUntil: Int): DataFrame = {
val range: Seq[Record] = (0 to rangeUntil).map(Record)
spark.createDataFrame(range).select(
f.col("value").alias(columnName)
)
}
}
There are multiple ways of how to wrap this code into a JAR. I decided to use sbt as it is the popular build system for Scala projects, but you may also use Gradle or any other tool.
-
Install IDE: Install IntelliJ IDEA Community Edition > Open > Install Scala Plugin
-
Create a project: Open IntelliJ IDEA > New Project > Scala > sbt > pick sbt 1.5.5 and Scala 2.12.15. Note that Spark is compatible with concrete versions of the Scala language. You may find which version to use at the official Spark website.
-
Configure build: We will use Spark 3.2.0. Add Spark to dependencies
// In build.sbt
val sparkVersion = "3.2.0"
// The dependencies are "provided" here because
// both spark-core and spark-sql are already available in PySpark
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core" % sparkVersion % "provided",
"org.apache.spark" % "spark-sql" % sparkVersion % "provided"
)
We will use the sbt-assembly plugin that will be able to put everything in a single JAR. Install the plugin by adding the following line to project/plugins.sbt
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "1.1.0")
That’s it! You may develop your library under src/main/scala folder and build a JAR with sbt assembly command.
Use the JAR in PySpark
To use the JAR dependency, let’s create a simple Python project and install pyspark==3.2.0 and pandas==1.3.4 (to use .toPandas() DataFrame method)
We create a Spark session first, adding the path to the JAR to the driver classpath.
spark = (SparkSession
.builder
.appName("app")
.master("local[2]")
.config(
"spark.driver.extraClassPath",
"/tmp/spark-sample-dep-1.0.jar") # Use correct path!
.getOrCreate())
Below you can see a rough schema of how PySpark session.
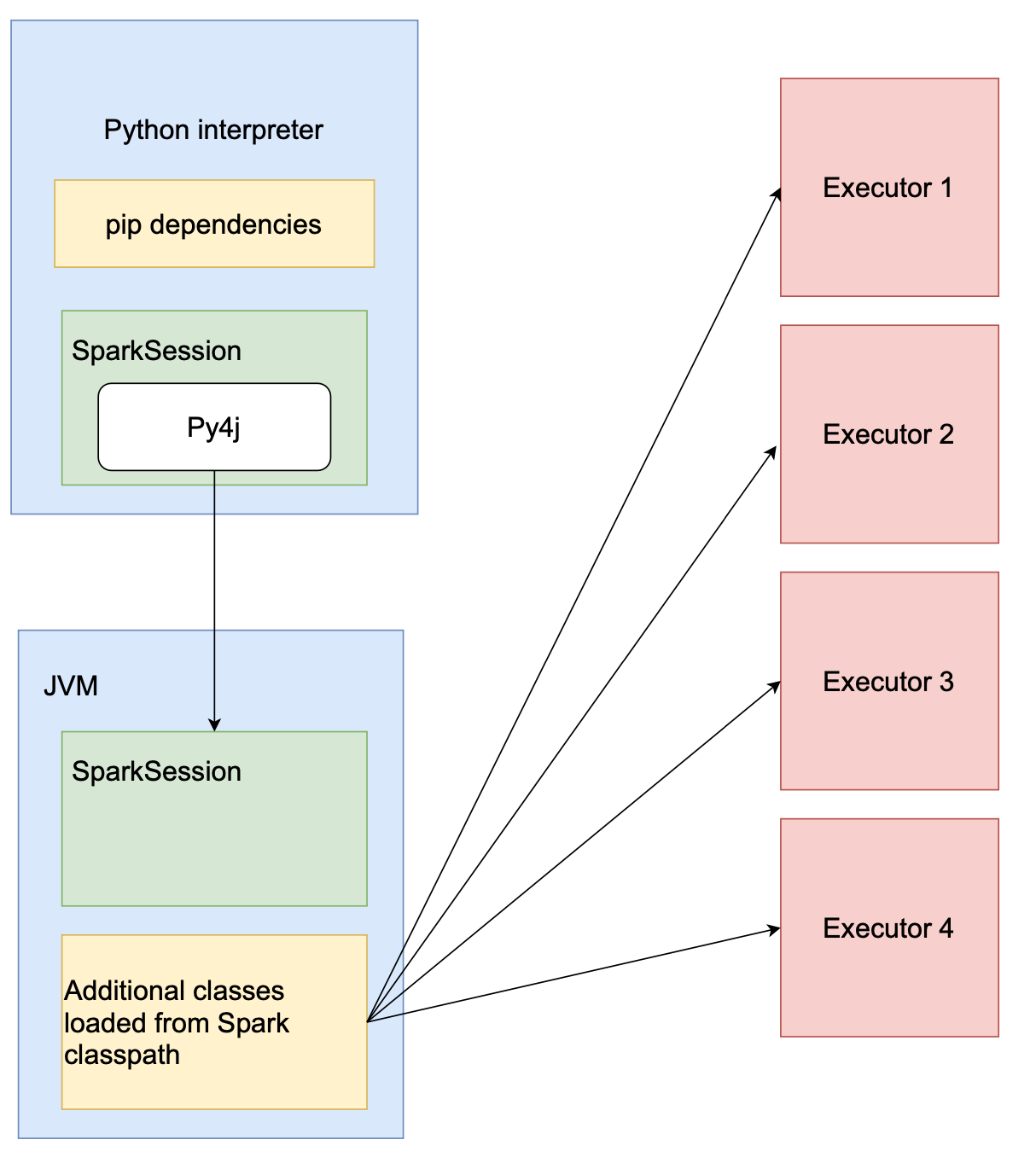
When the driver is started, PySpark launches a JVM through py4j and adds spark-sample-dep-1.0.jar to its classpath. That means that we can instantiate MySparkLibrary from Python and use it.
// lib is an instance of MySparkLibrary class wrapped by py4j.
lib = spark._jvm.org.sergey.MySparkLibrary()
Now, we can call the rangeDataframe method we’ve implemented.
# Note that py4j can convert Python strings and integers to
# Java types nativelly.
#
# On the other hand, we need to pass the JVM spark session instance
# to the method as the first argument.
jdf = lib.rangeDataframe(
# Get the wrapped JVM spark session and pass it
spark._jsparkSession,
# The 2nd and 3rd are primitives, OK to pass as is.
"range_column",
10
)
Note the returned jdf is not a PySpark DataFrame as it is a JVM object as well. (Try print(type(jdf)) , you’ll see something like <class 'py4j.java_gateway.JavaObject'> — a Java object wrapped by py4j). This is because rangeDataframe returns an object of Scala DataFrame type. The picture below shows how PySpark works with DataFrames. Each PySpark DataFrame is wrapped Scala DataFrame.
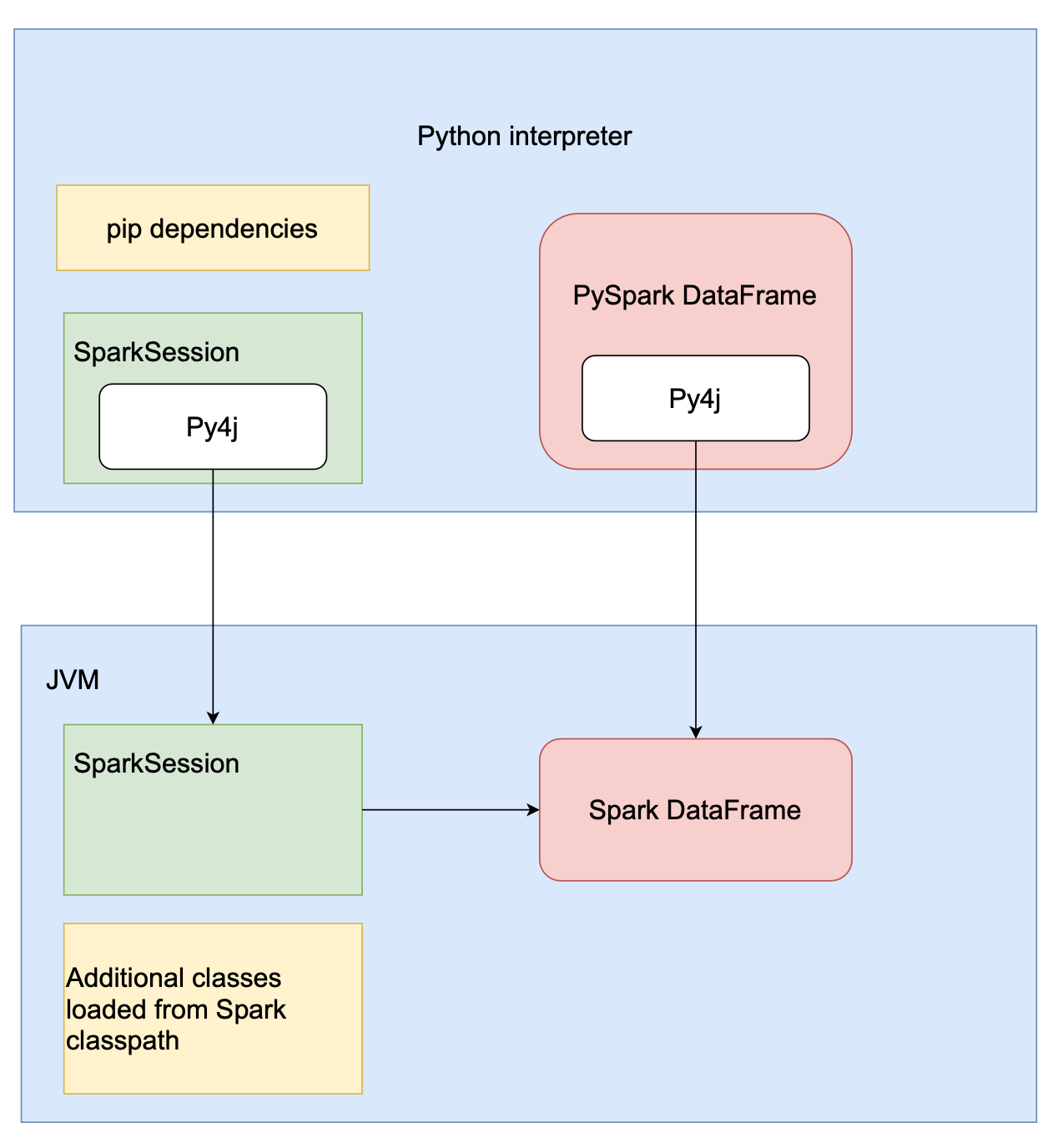
That means that we need to transform jdf to use it in Python. To wrap it with PySpark and receive a PySpark DataFrame object, we need to call a DataFrame constructor.
sql_context = SQLContext(spark.sparkContext, sparkSession=spark)
python_dataframe: DataFrame = DataFrame(java_dataframe, sql_context)
We’re done here! Try using the PySpark API and use the returned result.
print(python_dataframe.toPandas())
Passing DataFrame from Python to Scala
Imagine that we want another method that accepts a Spark DataFrame. How do we pass it from Python to our library? Let’s imagine that we implemented a super-fast DataFrame counting method.
# Scala
class MySparkLibrary {
...
def countFast(df: DataFrame): Int = {
// Not so fast :)
return df.count()
}
}
Then we can call this method from Python/PySpark like this
lib = spark._jvm.org.sergey.MySparkLibrary()
df: DataFrame = ... # PySparm dataframe
# df._jdf accesses the wrapped JVM dataframe object.
count = lib.countFast(df._jdf)
print(count)
That’s it! These techniques should be enough to develop reasonably complex Scala libraries for your PySpark project and not sacrifice performance!
Conclusion
In this article, we learned how to develop libraries in Scala using Spark and use them inside PySpark jobs.
You can find the source code of the examples above here.
Comments
0 published comments
No published comments yet.
Leave a comment
Comments are published after review.