Landing data on S3: the good, the bad, and the ugly

The prelude
Millions of users use Joom daily to find cheap products and to purchase them. The analytics and ML teams are essential in such a business in order to make reasonable business decisions, implement and test new features, make recommendations etc. To support these endeavors our internal data platform team builds scalable, maintainable, and durable data pipelines to publish the cleaned and trusted data sources with the analysts for them to do their work.
Any end-to-end data pipeline consumes the data from the outside world and ours is no exception. We use Apache Kafka as the asynchronous interface between the backend and analytics. Here’s a rough diagram of the architecture of this component
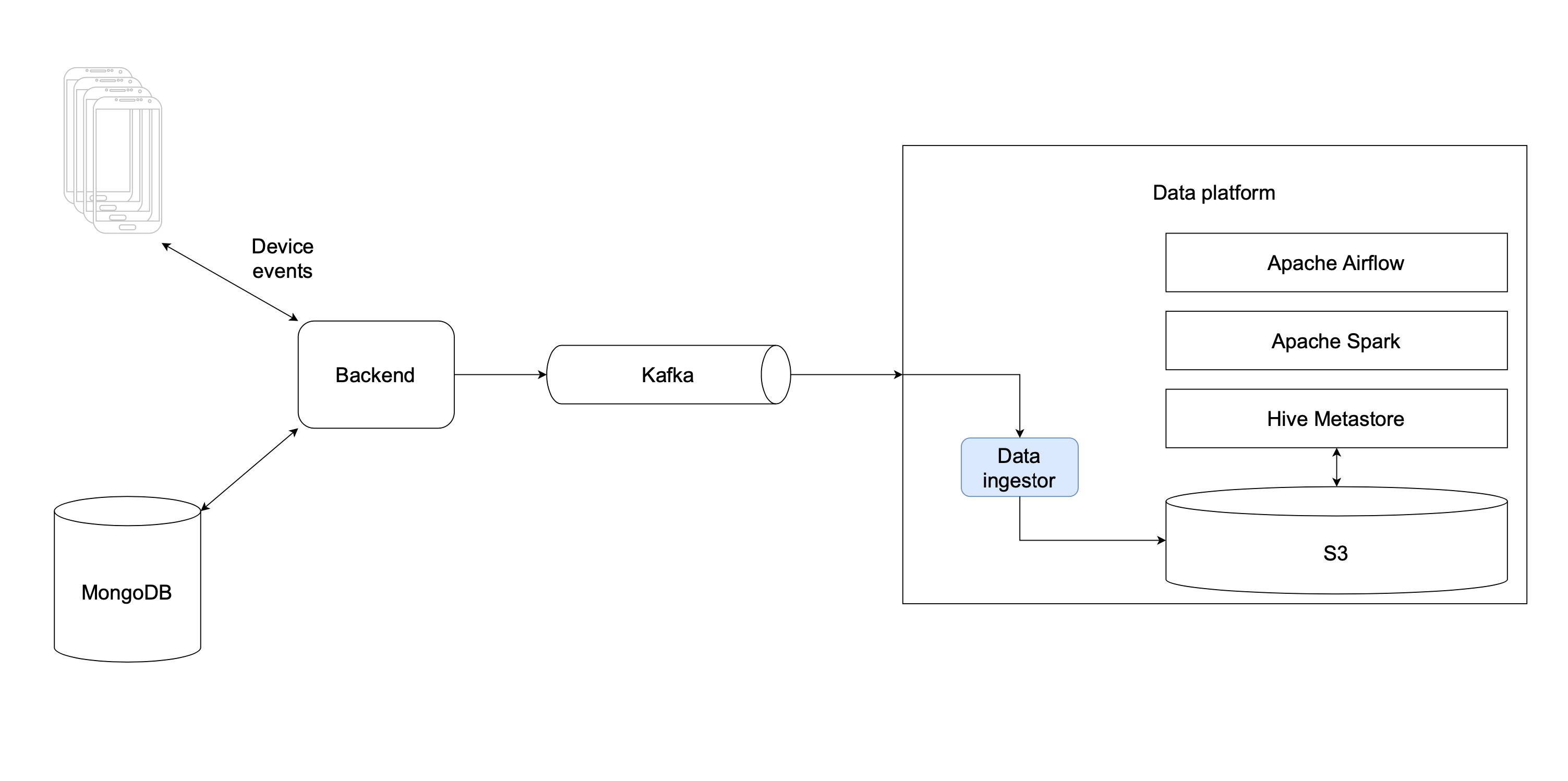
Apache Kafka is great for the data exchange in this case because having agreed on the schema of the records in the queue, the domain that produces them and the domain that consumes them can work independently.
Out data pipelines are built as a series of data manipulations with events and tables stored on S3, so the first thing our data platform needs to do is to land the raw events from the Kafka queue to S3.
This article describes how we approached the problem of landing the events, what went well, where we shot ourselves in the leg and what solutions we ended up with is.
The data ingestion requirements
The events that are piped into the Kafka queue, be it the events from the devices or the MongoDB collections change stream, have the following layout
{
"type": "TypeOfEvent",
"timestamp": "2021-01-01T01:00:00",
...
}
The ... denotes the payload of the event.
Events should be partitioned
The type of the event defines its schema. For example, if the type is urlClick then the schema of urlClick dictates that there’s a string field url in the payload of the record.
Not all types are born equal, some types of events generate considerably more data than the other ones. As an example, imagine you’re generating an event for each opening of the cart cartOpen and each tap. It’s obvious that you will end up with a great deal more tap events that cartOpen in your warehouse.
One consequence of this event amount imbalance in our case is that the data should be partitioned during landing on S3 so as the subsequent steps that process cartOpen events are not required to read all the data for processing.
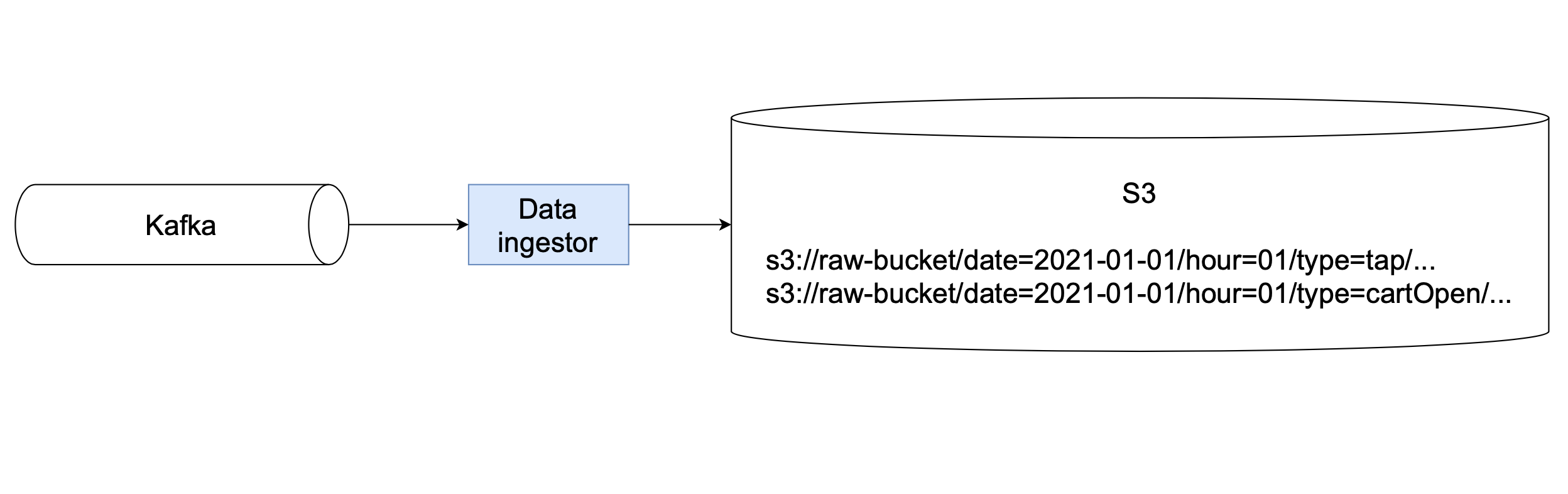
New Kafka topics can be added easily
Some groups of events might be published to different Kafka topics. Using a single topic for all the events
-
Not durable: data skew in any partition would affect all the data being exchanged.
-
Not debuggable: finding out and looking up specific records in Kafka sometimes requires a full scan of the topic. Using the sole topic would make this analysis very computationally expensive.
-
Not scalable: the pipelines that require reading data from Kafka would end up reading and filtering records they don’t need causing performance penalties for both consumers and the Kafka cluster.
Thus, the event ingestor needs to not only simultaneously read, partition, and write data from several topics, but also be extendible for new ones.
The ugly solution: Apache NiFi
Initially, we used Apache NiFi for data ingestion.
NiFi is a great data distribution and processing system. Among its strengths are
-
Excellent Web UI: lets users build, change, monitor their data pipelines without leaving the web interface. It manages to be friendly to people of different levels of technical skills and doesn’t sacrifice configurability.
-
High configurability: high latency or high throughput, you may choose for yourself. The NiFi does a great job at optimizing RAM usage by working with pointers to record in data streams instead of operating with whole files.
However, virtue always goes hand in hand with vice. Some issues arise as the result of the benefits of NiFi:
-
No benefits of the infrastructure-as-code approach. Changes to data flows cannot be reviewed, tracked down nor reproduced. These requirements are critical when building a shared data platform.
-
High disk I/O. Data processing in multi-stage data flows results in high disk usage because NiFi stores intermediate processing results on disk. In our experience, the write amplification effect reduced the throughput by 2x. If you’re running NiFi on AWS, prefer instances with local disk instead of EBS as it may improve the performance a great deal. On the other hand, this technique increases the costs and has its limits in terms of scalability. As a result, our desire was to drop the need for disks whatsoever.
The bad solution: Apache Flink
When we decided to search for alternatives, Flink had already been in use at Joom for real-time monitoring and threat detection for some time and worked great.
Apache Flink is a distributed computation framework that was initially built for streaming analysis. Flink operates with data streams —a sequence of records—in real-time and is easily scalable horizontally. You can express your logic in Scala, Java, and Python, and thus you can build the data ingestion pipeline and control it via configuration.
In core, the code that processes the data looks quite simple:
# Create data source.
val eventSource = new FlinkKafkaConsumer[Event](topics, deserializer, props)
val eventStream = see.addSource(eventSource)
# Create data destination
val sink = StreamingFileSink
.forBulkFormat[Event](
outputPath,
writer
)
.withBucketAssigner(bucketAssigner)
.withRollingPolicy(policy)
.build()
# Run pipeline
eventStream.addSink(sink).name("Fancy pipeline")
Two components here responsible for building the output files are bucket assigner and rolling policy
Bucket assigner
The buckets are the way to achieve partitioning of the output files. Bucket assigner groups the data by assigning a bucket to every record in the event stream.
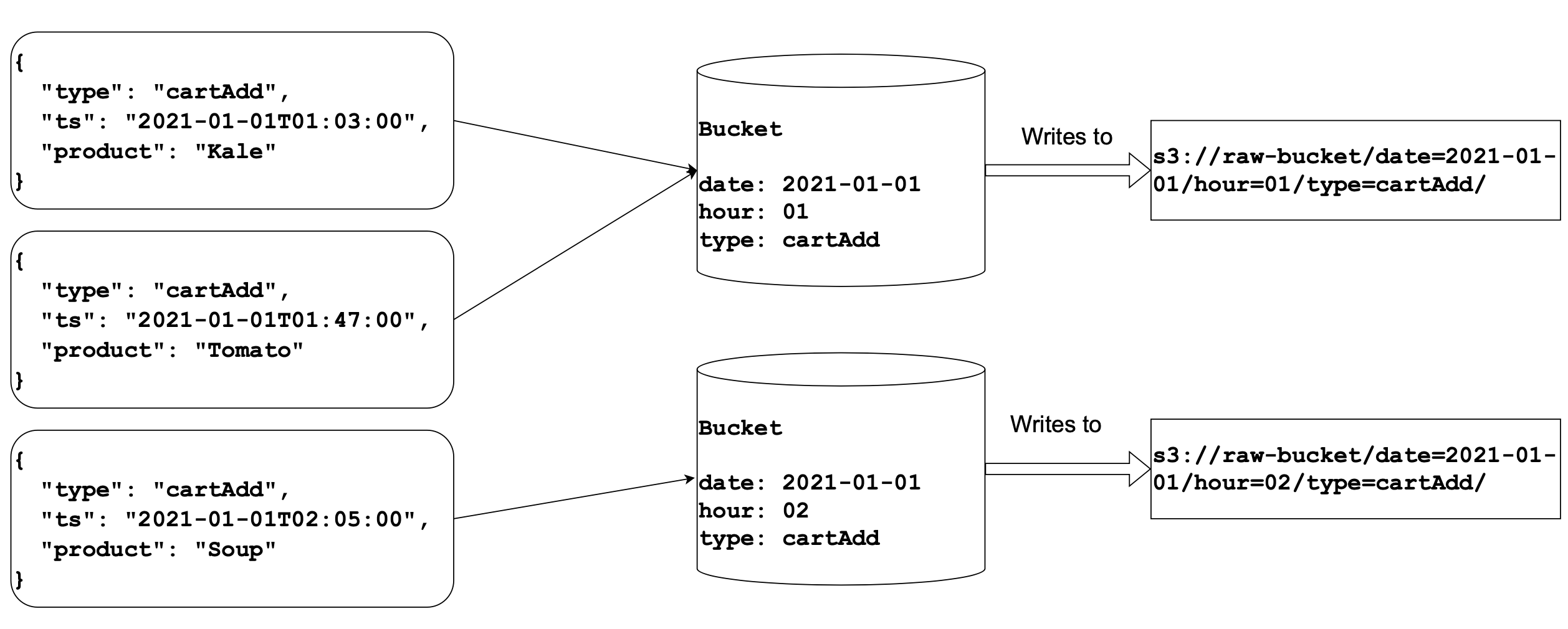
Every event is dispatched to a corresponding bucket that knows how (notice that we pass the writer to the sink builder) and where to write the event to. When a new bucket is created, it opens a file and writes events to it when they reach the bucket.
Rolling policy
But when the file opened by bucket needs to be flushed to the destination? Here comes the rolling policy. Based on the contents of the event, the file size, or the processing time (the time on the node processing the events) it can trigger the flush of the file to the disk.
This configuration comes in handy when you want to either meet some latency requirements (say, you want an event to be on disc within a 5-minute interval) or you want to reduce the number of output files by triggering write when the size of the file reaches the desired limit.
The result
Having implemented such a pipeline with external configuration using Flink 1.11.1 the solution proved to be
-
Computationally scalable. The pipeline can be scaled horizontally via adding TaskManagers (or simply workers). Flink is smart enough to parallelize Kafka partitions across TaskManagers and does not cause any shuffle.
-
Easily extendible. Add your topic and destination path to the config and restart the pipeline — adding new topics is that easy.
But the problems started to emerge, which we simply could not solve.
Issue 1: memory management
Flink memory management configuration is simply awful.
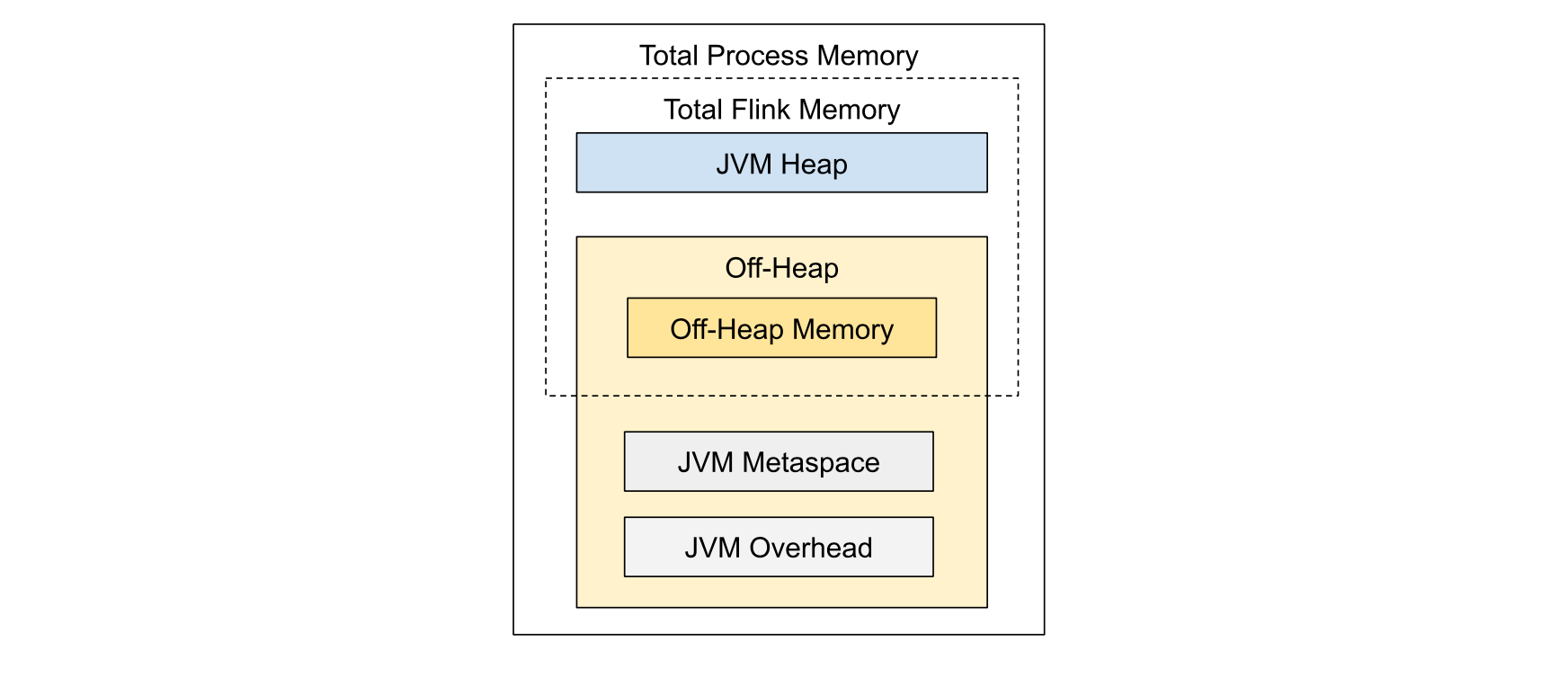
There are multiple documentation pages (example) you need to thoroughly read in order to
-
Realize that the default settings are awful for streaming pipelines (for example, half of RAM goes straight to the off-heap buffers that are used for batch operations by default)
-
Start your journey to the correct combination of these settings
taskmanager.memory.framework.off-heap.size
taskmanager.memory.task.off-heap.size
taskmanager.memory.network.fraction
taskmanager.memory.flink.size
taskmanager.memory.jvm-metaspace.size
taskmanager.memory.process.size
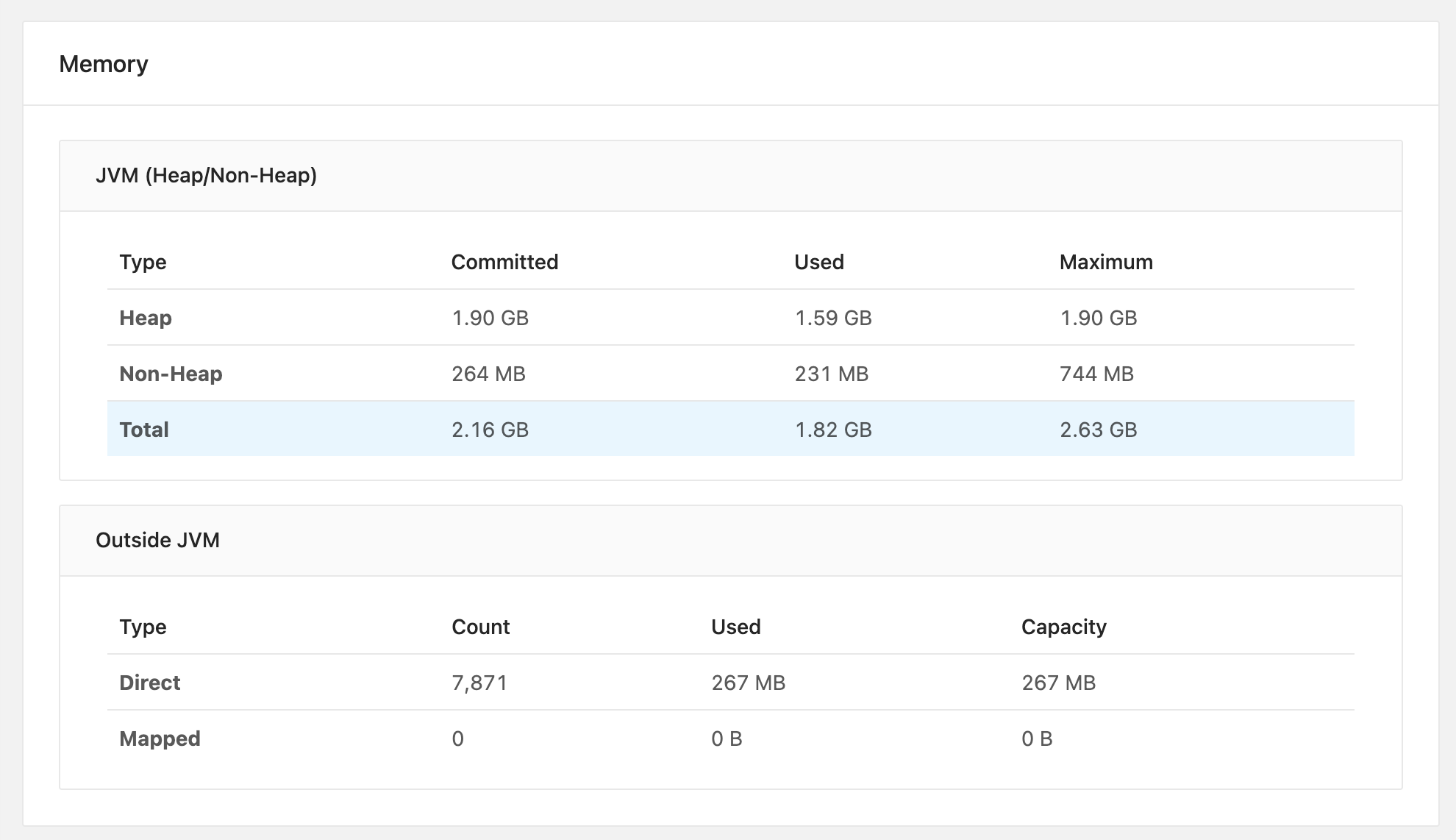
And even then you are not safe from occasional pipeline fails. According to our experience, write-intensive pipelines which include compression (as of version 1.11.1) contain hard-to-debug memory leaks that eventually cause jobmanager nodes to fail. We did not manage to find those in the end and ended up having to manually restart the pipeline once every few days in the worst case.
The Flink UI does a poor job at explaining the memory consumption: it’s very hard to understand even if the settings you provided correlate to the ones rendered by the Memory management page.
Issue 2: job interference
In cluster mode when you run multiple pipelines multiple types of resources are owned by the TaskManager and not the user code. For example, if a Job 1
-
opens a file descriptor (for example, via writing records via StreamingSink to a file)
-
Shuts down
The file descriptor does not get garbage collected since the reference to it is owned by the TaskManager that runs a JAR with your pipeline on the worker. In such a case running a different job might cause an obscure OOM error even the job itself doesn’t contain any bugs. In order to be sure that the memory gets cleaned you need to restart the TaskManager itself.
Issue 3: event backfill
Remember the rolling policy? Since the bucket-owned file gets shuffled only when some condition based on file size and the processing time is met. This is not enough when you want to backfill a big chunk of data corresponding to a long time interval. How do I configure Apache Flink's StreamingFileSink to use watermark for rolling in-progress files?
Let’s review an example: imagine you have a stream of events occurring once every hour for the past year and a rolling policy to flush files 5 minutes after creation. If these events are in Kafka topic, and you start the Flink ingestion pipeline, it will quickly process all 365 * 24 = 8760 events by
-
Creating a bucket for every hour (we partition events by date, hour, and type)
-
Open a file descriptor and create a compression buffer
-
Wait for rolling policy precondition to flush the file to the disk
In this example, you end up quickly opening 8760 file descriptors with compression buffers and then waiting 5 minutes doing nothing.
This example shows that in case of having many event types to backfill you may run out of RAM because your ingestion pipeline processes the events too fast. Since the rolling policy doesn’t take into account the event time (the actual timestamp written in the events) there’s no simple way around it.
Issue 4: success markers
Imagine that in the stream of events we encountered the first event cartOpen that lies in the 11th hour of 2021–01–01. Flink creates a bucket (cartOpen, 2021-01-01, 11), opens a file, and writes the event to it. After some time how does it know that no events will come to that bucket? How can the bucket report that all events have been written so that the consequent pipelines start processing the written events? It turns out we can’t do it without obscure heuristics.
In addition, even if your outputs are configured to be committed during Flink checkpoint, the actual file upload happens after the checkpoint is completed and can last for minutes, so there’s no guarantee that the data is persisted to S3 right after the checkpoint.
The good solution: Apache Spark
The problems faced during the operation of this pipeline encouraged us to find a simpler and more durable solution. Since we don’t need extremely low latency for event ingestion, the simple yet robust solution was right under our nose.
Apache Spark, the framework we use for batch data processing, supports reading records from Kafka in batch mode given either Kafka offset interval or starting and ending timestamps.
The following example reads an hour of events from Kafka topic1 that has two partitions:
import json
from datetime import datetime
# From 2020-01-01T01:00:00 to 2020-01-01T02:00:00
MILLISECONDS_IN_SECOND = 1000
start_ts = datetime.timestamp(datetime(2021, 1, 1, 1)) * MILLISECONDS_IN_SECOND
end_ts = datetime.timestamp(datetime(2021, 1, 1, 2)) * MILLISECONDS_IN_SECOND
# Compose the offset request string:
start_offsets = {"topic1": {"0": start_ts, "1": start_ts}}
end_offsets = {"topic1": {"0": end_ts, "1": end_ts}}
hour_of_data = (spark.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.option("startingOffsetsByTimestamp", json.dumps(start_offsets))
.option("endingOffsetsByTimestamp", json.dumps(end_offsets))
.load())
This approach is straightforward but there’s a performance issue if in the given hour there are too many records. The code above creates a Spark DataFrame with exactly two partitions
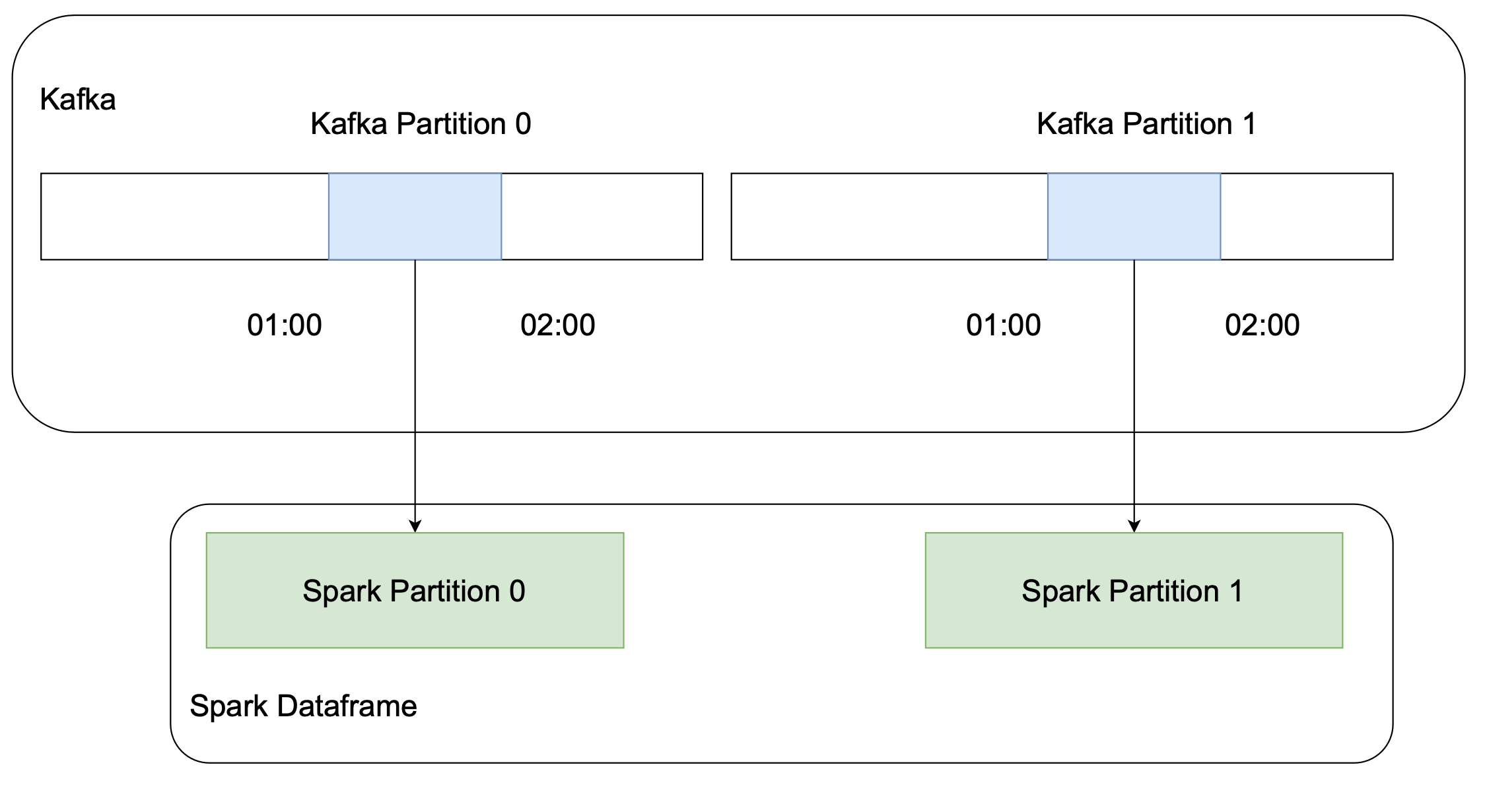
Two partitions mean two tasks reading the data from Kafka which might be far from perfect for achieving high throughput.
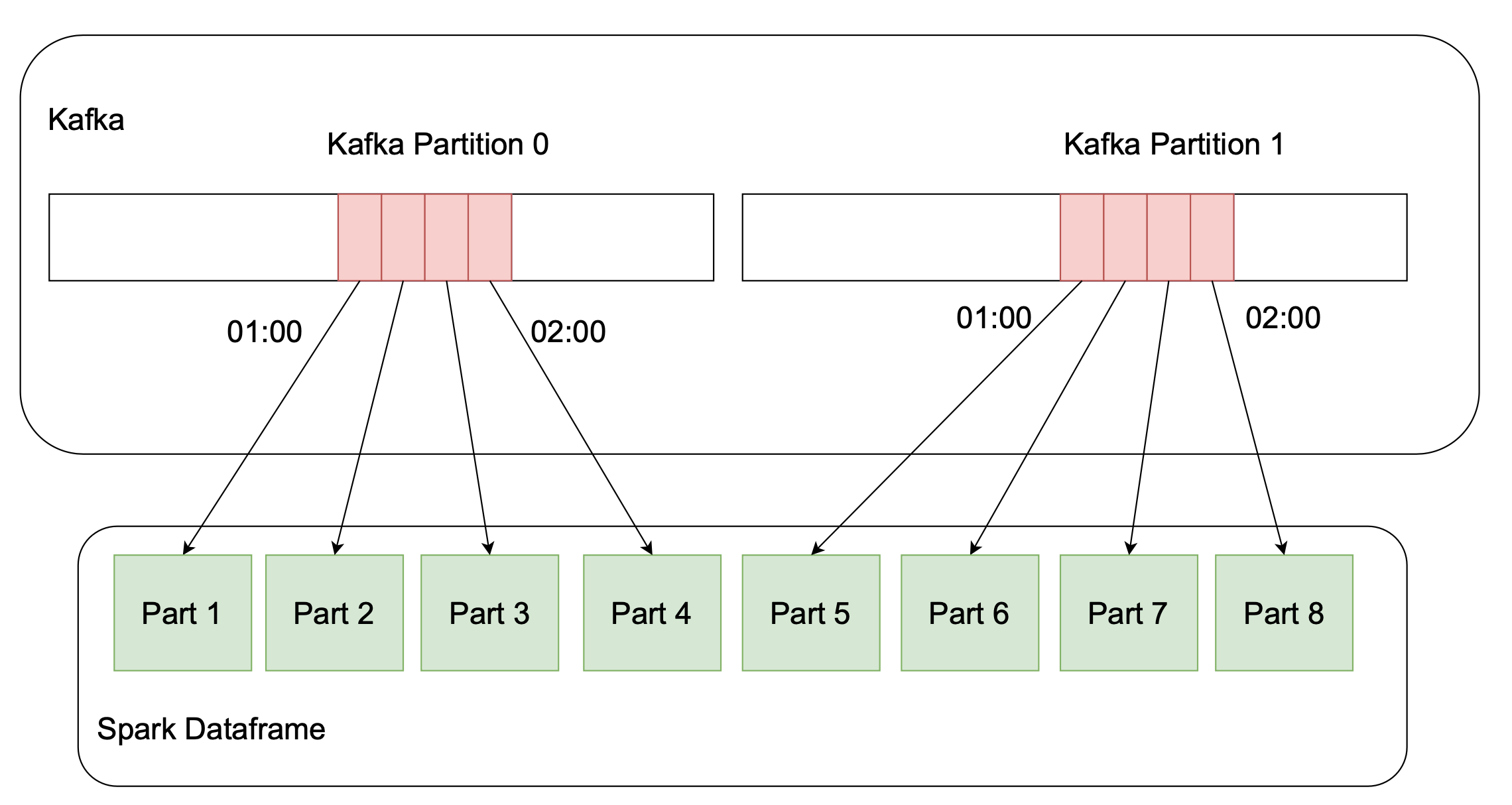
Divide and conquer
The idea is to divide the input slices based on the desired maximum number of rows per partition. Kafka API already has offsetForTimes() method which is what we need. The basic idea is:
-
For each partition for the desired time range fetch starting and ending offsets
-
Find max difference among offset pairs
-
Based on this and the desired number of rows find out how exactly we want to divide each partition. In our case, we simply divide each Kafka slice into N parts, where
N = max_difference / desired_rows_count -
Use
spark.read.format("kafka")withstartingOffsetsandendingOffsetsoptions for each for N combinations of partition-start offset-end offset pairs. Use .union to make the final dataset.
Here’s an example of how to fetch offsets using kafka-python library
from kafka import TopicPartition
from kafka import KafkaConsumer
from datetime import datetime
def get_offset_for_times(
consumer: kafka.KafkaConsumer,
ts: datetime):
offset_for_times_request = {
TopicPartition(topic, p): datetime.timestamp(ts) * 1000
for p in partitions
}
return consumer.offsets_for_times(offset_for_times_request)
consumer = KafkaConsumer(topic, bootstrap_servers=brokers)
start_offsets = get_offset_for_times(consumer, start_ts)
end_offsets = get_offset_for_times(consumer, end_ts)
Using the returned offsets it’s easy to find out the exact offset ranges you need to read via spark. The partitioning and writing to S3 using Spark is simple and I won’t dig into details on how to do it.
The last step would be to make an Airflow dag out of this job and run it hourly.
The conclusion
In this article, I described our journey towards the data ingestion pipeline. The final iteration turned out to be an hourly Spark pipeline that reads hour long data slices directly from Kafka.
-
Scalable: during reading, the number of spark tasks scales horizontally based on the rows being read.
-
Reliable: Spark pipelines are proven to be durable. We encounter less obscure and hard-to-debug bugs in the current solution.
-
Extendible: an Airflow DAG can be extended with more tasks and works as an ingestion config.
-
Backfill works: the code above can be run with any time range.
-
Downstream jobs start immediately: spark writer adds SUCCESS marker to S3 that can be easily listened to by a Flink sensor to start subsequent tasks.
Comments
0 published comments
No published comments yet.
Leave a comment
Comments are published after review.